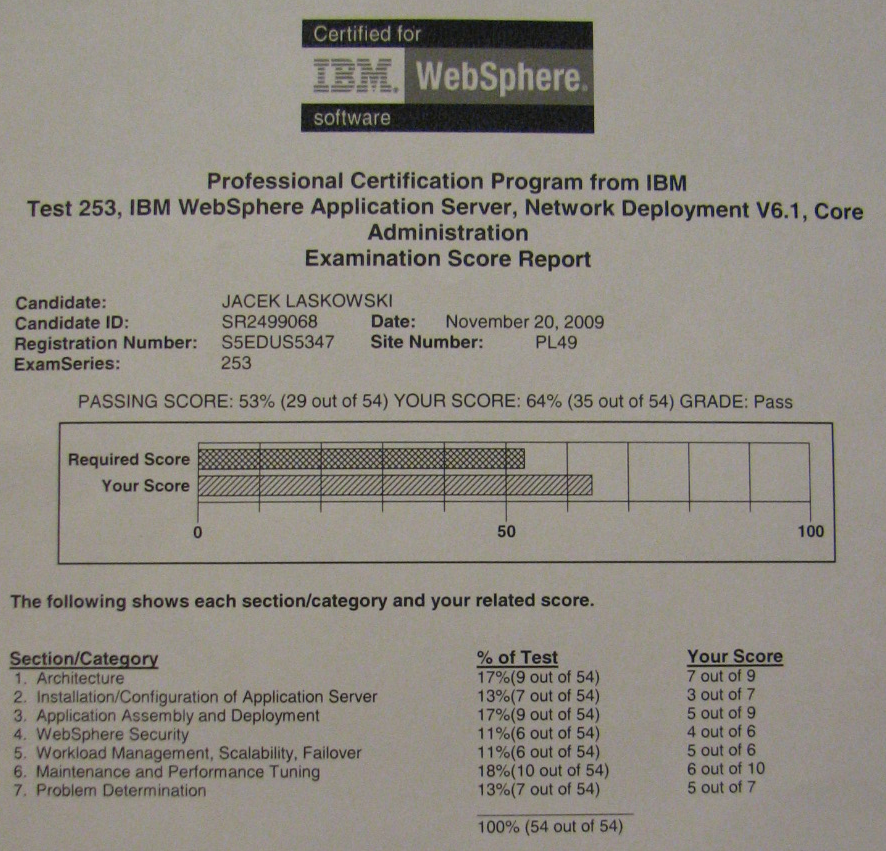
Zgodnie z sugestią
Michaela zabrałem się za poznawanie Clojure od strony jego kodu źródłowego i podążając słowami mojego mistrza zabrałem się za makro
->, zwane również w kręgach Clojure jako makro
"thread".
Kod źródłowy jest niezwykle mały i znajduje się w repozytorium Git -
core.clj.
(defmacro ->
"Threads the expr through the forms. Inserts x as the
second item in the first form, making a list of it if it is not a
list already. If there are more forms, inserts the first form as the
second item in second form, etc."
([x form] (if (seq? form)
`(~(first form) ~x ~@(next form))
(list form x)))
([x form & more] `(-> (-> ~x ~form) ~@more)))
Forma
doc zwraca
Clojure doc, czyli dokumentację funkcji będącej jej argumentem wejściowym, więc i bez kodu źródłowego możnaby się doczytać, co autor miał na myśli tworząc makro -> (mi to nie wystarczyło, ale pomyślałem, że wspomnę i o tej możliwości).
user=> (doc ->)
-------------------------
clojure.core/->
([x form] [x form & more])
Macro
Threads the expr through the forms. Inserts x as the
second item in the first form, making a list of it if it is not a
list already. If there are more forms, inserts the first form as the
second item in second form, etc.
nil
Czytając dokumentację dosłownie, makro -> ma za zadanie wpleść wyrażenie do listy form. Wciąż mi to jednak niewiele mówi. Definicja -> składa się z dwóch przypadków - kiedy makro dostaje na wejściu dwa parametry i więcej.
Forma (ang.
form) to po prostu dwa nawiasy, w których są wywołania funkcji czy makr, lub ponownie form. I tak rekurencyjnie mamy całą masę par nawiasów. W Clojure *wszystko* jest w nawiasach, albo zastąpione pewnymi specjalnymi konstrukcjami - uproszczeniami rozpoznawanymi przez kompilator, które wychodzą poza ten schemat, np. przywoływana już konstrukcja tworzenia kluczy :nazwa jest równoznaczna z wywołaniem funkcji
(keyword "nazwa") (często nazywanymi po angielsku
"syntactic sugar").
Wykonanie -> z jednym parametrem, to po prostu jego zwrócenie.
user=> (-> 2)
2
To było proste! :) Teraz będzie znacznie trudniej. Jeśli na wejściu -> mamy dwa parametry, to rozpatrujemy przypadki - 1) forma jest sekwencją (
seq? zwraca prawdę) i 2) kiedy nie jest. Przy okazji, nazwy funkcji, których wynikiem jest wartość logiczna true/false są zakończone
? (znak zapytania).
Weźmy ponownie coś równie prostego jak poprzednio.
user=> ; w nawiasie mamy funkcję minus i jej jedyny argument 3
user=> (-> 2 (- 3))
-1
Dlaczego? Analizując kod źródłowy -> dochodzimy do wniosku, że jest to równoznaczne z poniższym.
user=> (- 2 3)
-1
Pierwszy argument dla -> jest na drugiej pozycji w pierwszej formie, którą było (- 3). Można jeszcze sprawdzić, jaki był wynik if'a w makro ->.
user=> (seq? (- 3))
false
Zatem wyliczenie (-> 2 (- 3)) sprowadza się do konstrukcji (list form x), tj. (list - 3 2), a to daje:
user=> (list - 3 2)
(#<core$___4506 clojure.core$___4506@16de49c> 3 2)
Sprawdźmy, co da wywołanie tego funkcją
eval.
user=> (eval (list - 3 2))
1
Źle! Chyba popełniłem jakiś błąd w rozumowaniu, jaki argument jest przekazywany do seq?, bo w końcu zgodnie z definicją formy, zapis (- 3) nią jest! Biorąc więc pod uwagę moje niedoświadczenie i możliwe pomyłki w rozumowaniu, wchodzimy w sekcję if'a, bo wtedy wszystko jest cacy - 2 staje się drugim argumentem dla odejmowania, a 3 trzecim. Owe szlaczki w makro to sposób na tworzenie kodu w fazie wczytywania programu w Clojure (zaraz przez kompilacją i uruchomieniem), w której następuje rozwiązywanie makr, których celem jest uproszczenie życia programistom przez generowanie bardziej złożonego kodu (po co klepać kilkakrotnie to samo w wielu liniach, jeśli możemy zdefiniować makro raz i wywoływać wielokrotnie w jednej?! "Cudo" znane programistom C/C++).
Wciąż jednak nie rozumiałem, co jest takiego specjalnego w tym makro, aż trafiłem na
LexParse, gdzie padła wzmianka o
potoku (ang.
pipeline). Teraz było znacznie łatwiej zrozumieć, co autor miał na myśli. Aczkolwiek do pełnego zrozumienia daleko (pewnie za mało wciąż napisanych programów w Clojure).
user=> (-> 2 {2 "dwa"} {"dwa" "DWA"})
"DWA"Spróbuj samodzielnie znaleźć odpowiedź dlaczego w wyniku otrzymaliśmy "DWA", albo poniżej true:
user=> (-> '(0 0 0) (count) (odd?))
true
Doświadczenia z Clojure skończyłem artykułem
Clojure - Functional Programming for the JVM, którego autorem jest
R. Mark Volkmann. Tam znalazłem wzmiankę o
Simon Peyton-Jones, który włożył wiele wysiłku w Haskella (czysty język funkcyjny) i miał powiedzieć w
OSCON 2007 - Simon Peyton-Jones - A Taste of Haskell Part I:
"In the end, any program must manipulate state. A program that has no side effects whatsoever is a kind of black box. All you can tell is that the box gets hotter."i dalej już od autora artykułu:
The key is to limit side effects, clearly identify them, and avoid scattering them throughout the code. Warto również wspomnieć o leniwym rozwiązywaniu/wyliczaniu sekwencji -
leniwych sekwencjach (ang.
lazy sequences) (a może trafniej będzie nazywać je opóźnionymi czy nawet ospałymi czy w końcu uśpionymi sekwencjami?). Elementy w sekwencji nie są wyliczane, aż do momentu ich użycia, co pozwala na tworzenie nieskończonych ciągów danych bez narażania się na wysycenie sterty pamięci JVM. Ta cecha Clojure uzmysłowiła mi o możliwym podejściu w Javie, w której zwykle (zawsze?) wyliczamy wszystkie elementy, nawet jeśli ich nie potrzebujemy. Weźmy za przykład tablicę 150-elementową, albo jeszcze dłuższą. W Javie, w zależności od typu elementów, wielkość potrzebna na ich przechowanie musi być dostępna w trakcie deklaracji. Alternatywą mogłoby być stworzenie takiej kolekcji, w której podajemy liczbę elementów i tyle, a kiedy potrzebny będzie piąty, dziesiąty, czy którykolwiek inny element, wyliczamy go dokładnie w momencie zapytania o niego. Nie sądzę, abym kiedykolwiek myślał o programowaniu w Javie w ten sposób (może dlatego, że po prostu nie miałem okazji?!). Na szczęście nie musimy już tego implementować w Javie, bo mamy Clojure, więc chociażby dla tego warto zwrócić się ku niemu.
Bardzo przypadł mi do gustu następujący akapit:
Is Clojure code hard to understand? Imagine if every time you read Java source code and encountered syntax elements like if statements, for loops, and anonymous classes, you had to pause and puzzle over what they mean. There are certain things that must be obvious to a person who wants to be a productive Java developer. Likewise there are parts of Clojure syntax that must be obvious for one to efficiently read and understand code.Podobnie będzie z dowolnym językiem mówionym - angielski prosty, niemiecki również, pewnie podobnie z francuskim, czy hiszpańskim, nie wspominając o rosyjskim czy w ogóle słowiańskich. Nasłuchaliśmy się ich wokoło i teraz po prostu przywykliśmy do ich konstrukcji. Brakuje nam zrozumienia ich semantyki, więc chodzimy na drogie kursy licząc, że cudem bez specjalnego wysiłku mentalnego wejdą nam w przysłowiowe 5 minut. Wtedy również zadamy sobie pytanie o sensowność nauki kolejnego języka skoro mówimy, piszemy i czytamy po angielsku. Przypomina mi to pytanie o sensowność uczenia się Clojure. Po co się go uczyć skoro znamy Javę? Po co uczyć się kolejnego języka mówionego, znając angielski? Dla mnie, odpowiedź nasuwa się sama - z ciekawości, co tracimy nie potrafiąc posługiwać się językiem, którym władają inni. Czy Clojure jest tym językiem, który należałoby poznać? Nie wiem. Wiem jednak, że należy chociażby spróbować zrozumieć programowanie funkcyjne, aby zastosować go tam, gdzie programowanie obiektowe czy imperatywne nie przystaje. Jeśli znamy tylko OO, to jak tu mówić o zdrowym rozsądku? Dobrze ujął to
Abraham Maslow:
I suppose it is tempting, if the only tool you have is a hammer, to treat everything as if it were a nail.bądź, jak to jest częściej przywoływane:
If the only tool you have is a hammer, you tend to see every problem as a nail.Niestety nie wiem, jak miałoby to brzmieć po polsku :(
Właśnie kiedy miałem opublikować wpis, zajrzałem jeszcze do źródeł Clojure i trafiłem na funkcję
clojure-version. Trywialna, aczkolwiek wciąż pouczająca implementacja (której pewnie jeszcze samodzielnie nie dałbym rady napisać):
user=> (clojure-version)
"1.1.0-alpha-SNAPSHOT"
Jeśli doczytałeś/-aś do tego miejsca, to może i wytrwałeś/-aś z czytaniem podanego wyżej artykułu o Clojure. Jeśli tak, to w sekcji o mapach (Maps) jest wzmianka o...makrze -> (!)
The -> macro, referred to as the "thread" macro, calls a series of functions, passing the result of each as an argument to the next. For example the following lines have the same result:
(f1 (f2 (f3 x)))
(-> x f3 f2 f1)Teraz już jest jasne, co makro -> robi. W ramach nauki Clojure pozostaje więc nauczyć się jego implementacji na pamięć, aby kolejnym razem napisać podobne.
 Dzięki uprzejmości mojej korporacji, zamiast zajmować się przygotowaniami do warsztatów grailsowych na Uniwersytecie Opolskim, zabawiam się Makiem (!) I tak długo wytrzymałem, bo mam go od 3 dni, a jedynie co, to włączyłem go raz, może dwa razy i tyle. Dzisiaj jednak nie wytrzymałem - wymieniłem tego 3-dniowca na nowiutkiego z pudełka. I tak się zaczęło. Ten wpis idzie wprost z niego. Tutaj nawet pisanie stanowi wyzwanie. Nie wspomnę o menu u góry, czy te gesty na gładziku! Zresztą zobaczcie sami na filmiku - na tej stronie (szukajcie "Multi-Touch Trackpad"). A żebym wiedział, jak przejść na koniec linii?! A zrobienie zrzutu ekranu "kosztowało" mnie wizytę na Taking Screenshots in Mac OS X ;-)
Dzięki uprzejmości mojej korporacji, zamiast zajmować się przygotowaniami do warsztatów grailsowych na Uniwersytecie Opolskim, zabawiam się Makiem (!) I tak długo wytrzymałem, bo mam go od 3 dni, a jedynie co, to włączyłem go raz, może dwa razy i tyle. Dzisiaj jednak nie wytrzymałem - wymieniłem tego 3-dniowca na nowiutkiego z pudełka. I tak się zaczęło. Ten wpis idzie wprost z niego. Tutaj nawet pisanie stanowi wyzwanie. Nie wspomnę o menu u góry, czy te gesty na gładziku! Zresztą zobaczcie sami na filmiku - na tej stronie (szukajcie "Multi-Touch Trackpad"). A żebym wiedział, jak przejść na koniec linii?! A zrobienie zrzutu ekranu "kosztowało" mnie wizytę na Taking Screenshots in Mac OS X ;-) Jakby tego było mało, wczoraj O'Reilly wysyłał wiadomość z informacją o książce Grails -
Jakby tego było mało, wczoraj O'Reilly wysyłał wiadomość z informacją o książce Grails -